NVIDAI的AI画笔又进化了,这个视频演示了这款新画笔的威力:NVIDIA’s New AI: Next Level Image Editing! 👌 – YouTube
https://www.youtube.com/watch?v=cS4jCvzey-4
The paper “EditGAN: High-Precision Semantic Image Editing” is available here:
- https://nv-tlabs.github.io/editGAN/
- https://arxiv.org/abs/2111.03186
- https://github.com/nv-tlabs/editGAN_r…
- https://nv-tlabs.github.io/editGAN/ed…
以下为NVIDIA的论文:EditGAN (nv-tlabs.github.io)
NeurIPS 2021
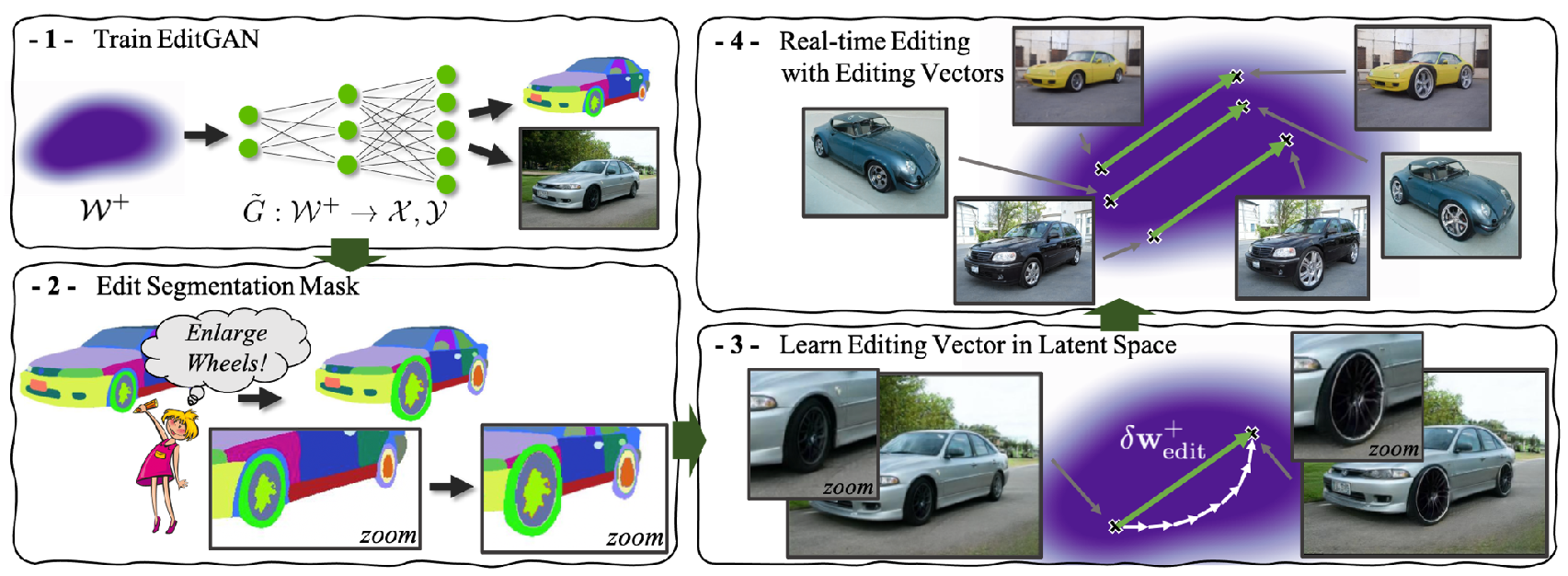 (1) EditGAN builds on a GAN framework that jointly models images and their semantic segmentations. (2 & 3) Users can modify segmentation masks, based on which we perform optimization in the GAN’s latent space to realize the edit. (4) Users can perform editing simply by applying previously learnt editing vectors and manipulate images at interactive rates. (1) EditGAN builds on a GAN framework that jointly models images and their semantic segmentations. (2 & 3) Users can modify segmentation masks, based on which we perform optimization in the GAN’s latent space to realize the edit. (4) Users can perform editing simply by applying previously learnt editing vectors and manipulate images at interactive rates. |
Generative adversarial networks (GANs) have recently found applications in image editing. However, most GAN-based image editing methods often require large-scale datasets with semantic segmentation annotations for training, only provide high level control, or merely interpolate between different images. Here, we propose EditGAN, a novel method for high-quality, high-precision semantic image editing, allowing users to edit images by modifying their highly detailed part segmentation masks, e.g., drawing a new mask for the headlight of a car. EditGAN builds on a GAN framework that jointly models images and their semantic segmentations (DatasetGAN), requiring only a handful of labeled examples – making it a scalable tool for editing. Specifically, we embed an image into the GAN’s latent space and perform conditional latent code optimization according to the segmentation edit, which effectively also modifies the image. To amortize optimization, we find “editing vectors” in latent space that realize the edits. The framework allows us to learn an arbitrary number of editing vectors, which can then be directly applied on other images at interactive rates. We experimentally show that EditGAN can manipulate images with an unprecedented level of detail and freedom, while preserving full image quality. We can also easily combine multiple edits and perform plausible edits beyond EditGAN’s training data. We demonstrate EditGAN on a wide variety of image types and quantitatively outperform several previous editing methods on standard editing benchmark tasks.
EditGAN is the first GAN-driven image editing framework, which simultaneously (i) offers very high-precision editing, (ii) requires only very little annotated training data (and does not rely on external classifiers), (iii) can be run interactively in real time, (iv) allows for straightforward compositionality of multiple edits, (v) and works on real embedded, GAN-generated, and even out-of-domain images.
News
- [February 2022] Code released on Github!
- [January 2022] EditGAN featured in NVIDIA Developer Blog!
- [November 2021] Project page released!
- [November 2021] Paper released on arXiv!
- [September 2021] Paper accepted to Advances in Neural Information Processing Systems (NeurIPS) 2021!
Paper
 |
EditGAN: High-Precision Semantic Image EditingHuan Ling*, Karsten Kreis*, Daiqing Li, Seung Wook Kim, Antonio Torralba, Sanja Fidler* Authors contributed equallyAdvances in Neural Information Processing Systems (NeurIPS), 2021 [Paper] [Code and Interactive Editing Tool] For feedback and questions please reach out to Huan Ling and Karsten Kreis. |
|||
Demos
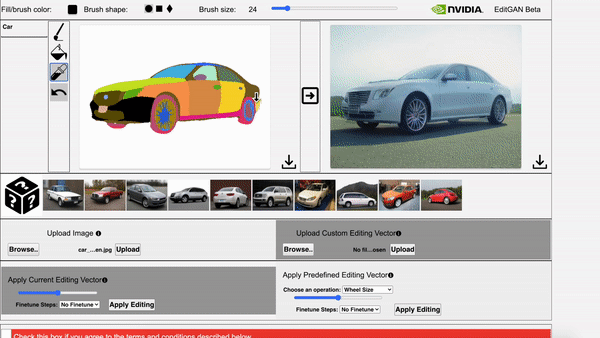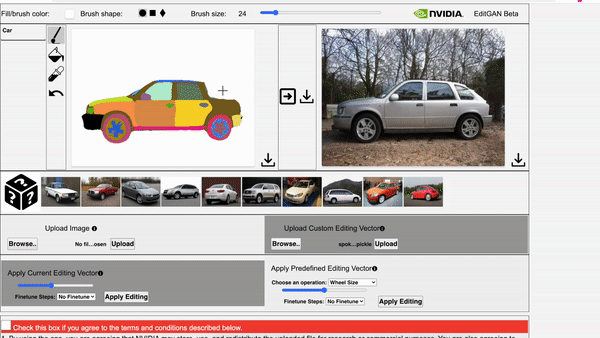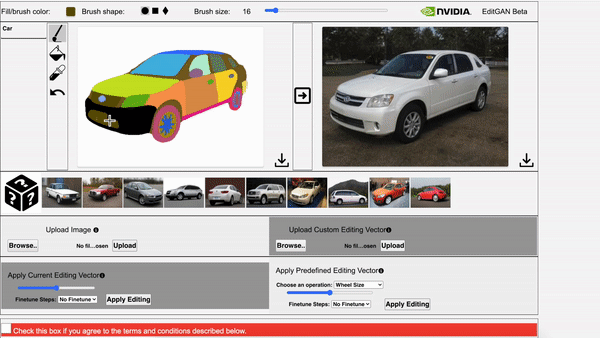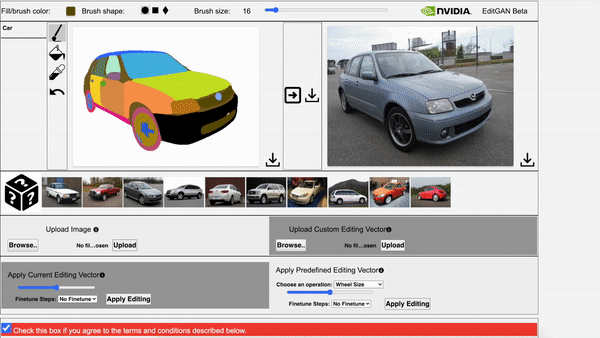
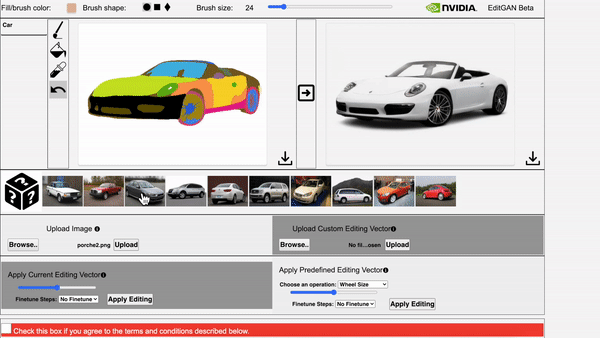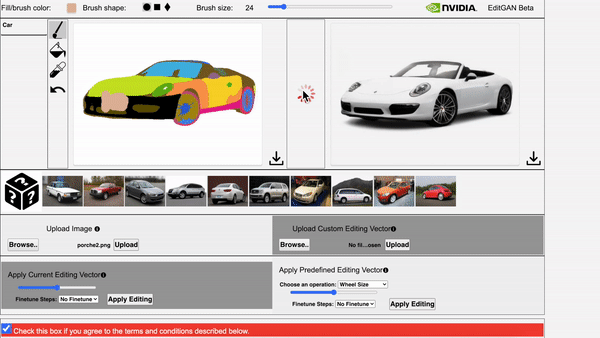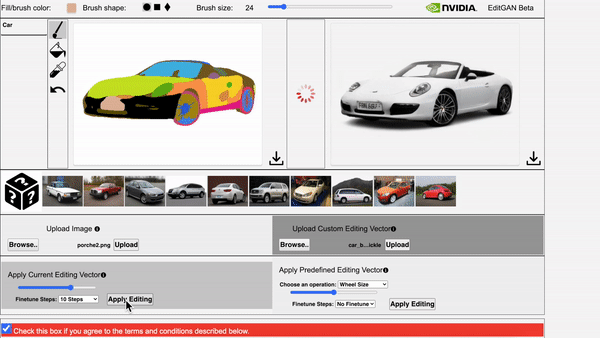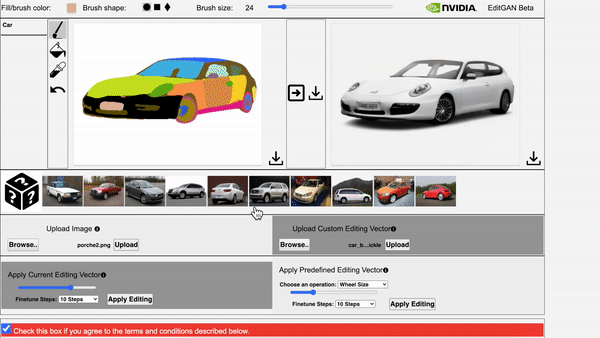
Left: The video showcases EditGAN in an interacitve demo tool. Right: The video showcases EditGAN where we apply multiple edits and exploit pre-defined editing vectors.


Left: The video shows interpolation of editing vectors. Right: The video shows the result of applying EditGAN editing vectors on out-of-domain images.
Results



Citation
@inproceedings{ling2021editgan,
title = {EditGAN: High-Precision Semantic Image Editing},
author = {Huan Ling and Karsten Kreis and Daiqing Li and Seung Wook Kim and Antonio Torralba and Sanja Fidler},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2021}
}
Also see prior work on efficient semantic segmentation using GANs, which EditGAN builds on:
@inproceedings{zhang2021datasetgan,
title={DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort},
author={Zhang, Yuxuan and Ling, Huan and Gao, Jun and Yin, Kangxue and Lafleche,
Jean-Francois and Barriuso, Adela and Torralba, Antonio and Fidler, Sanja},
booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2021}
}
@inproceedings{li2021semantic,
title={Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization},
booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)},
author={Li, Daiqing and Yang, Junlin and Kreis, Karsten and Torralba, Antonio and Fidler, Sanja},
year={2021}
}